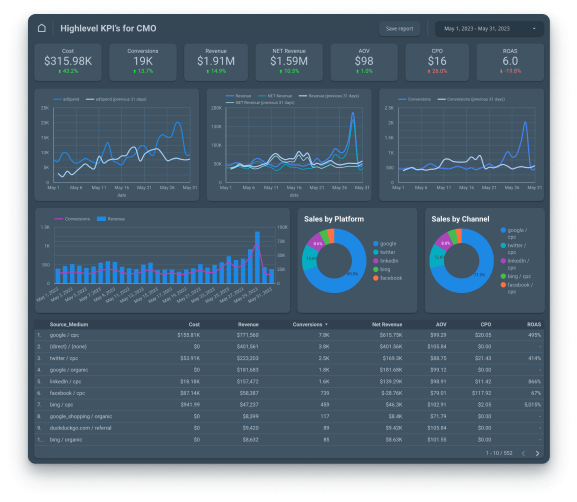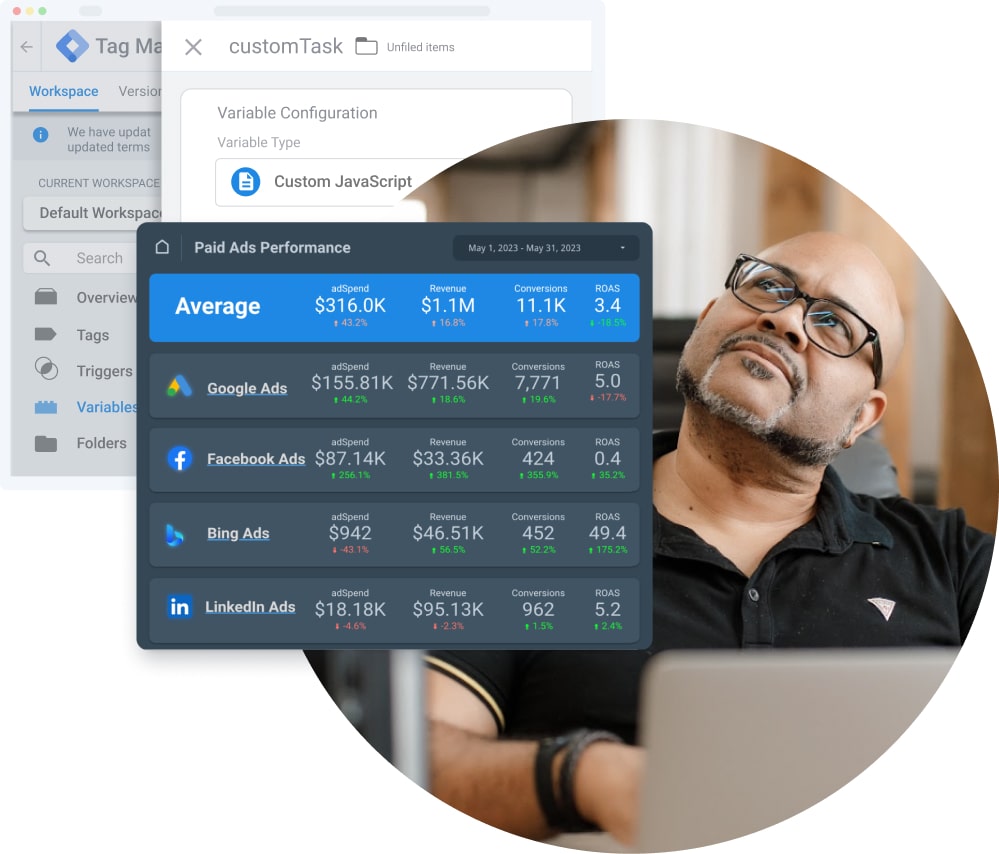
Reduce time spent on reporting
Spend more time reaching your monthly KPIs, instead of collecting the data or buildingreports
Make data-driven decisions
Merge advertising data, user behavior, and CRM in one report for a comprehensive overview of your performance
Control Cross-channel spend
Take full control of your marketing budget and make sure every dollar is spent wisely
Grow revenue
Evaluate user behavior and conversion data to discover and boost your most-performing marketing channels
Establish a single source of truth
Create a single source of truth between departments, ensuring everyone is on the same page